All scientific and clinical disciplines are currently “drowning” in an overwhelming amount of information, far more than can be used productively. This issue can be traced to the limitations of human memory, where human working memory is about 10+20 times smaller than the internet, akin to a 1-liter bottle floating in the vast Atlantic Ocean. While statistical methods are critical to “swim these waters,” Automated Software Tools are essential for applying these methods at scale. Additionally, Data Maps are crucial for helping investigators understand what data is available and what is not, enabling them to effectively utilize statistical and software tools to answer their scientific questions. The figure to the right illustrates these challenges using a sailing analogy where statistics is equivalent to swimming, software tools are equivalent to sailing, and “big data” navigation requires a world map. The objective of the Systems Modeling and Data Analytics Core (SMDA) is to aid data-centric research at UGA by mapping discipline- and data-specific expertise and providing software, training, and collaborative tools to sail the waters of biomedical big data.
All scientific and clinical disciplines are currently “drowning” in an overwhelming amount of information, far more than can be used productively. This issue can be traced to the limitations of human memory, where human working memory is about 10+20 times smaller than the internet, akin to a 1-liter bottle floating in the vast Atlantic Ocean. While statistical methods are critical to “swim these waters,” Automated Software Tools are essential for applying these methods at scale. Additionally, Data Maps are crucial for helping investigators understand what data is available and what is not, enabling them to effectively utilize statistical and software tools to answer their scientific questions. The figure to the right illustrates these challenges using a sailing analogy where statistics is equivalent to swimming, software tools are equivalent to sailing, and “big data” navigation requires a world map. The objective of the Systems Modeling and Data Analytics Core (SMDA) is to aid data-centric research at UGA by mapping discipline- and data-specific expertise and providing software, training, and collaborative tools to sail the waters of biomedical big data.
Working Group Architecture of SMDA core:
Critically, different disciplines and different data types require distinct maps and software tools to answer domain-specific questions. The proposed architecture for the Systems Modeling and Data Analytics (SMDA) core is based on the software-engineering project-management principles described in “The Mythical Man Month” and modeled after the National Institutes of Health’s (NIH) CTD2 collaborative network of data-driven research centers. A core thesis underlying both initiatives is that information-heavy projects operate most efficiently with small working groups (~8 people per group) and efficient communication between working groups, which is the primary goal of leadership and core infrastructure, such as a dedicated website. The core idea is that communication, rather than labor, is the biggest challenge with large team projects. The graphic below illustrates the current working group structure identified to reconcile investigators within SMDA:

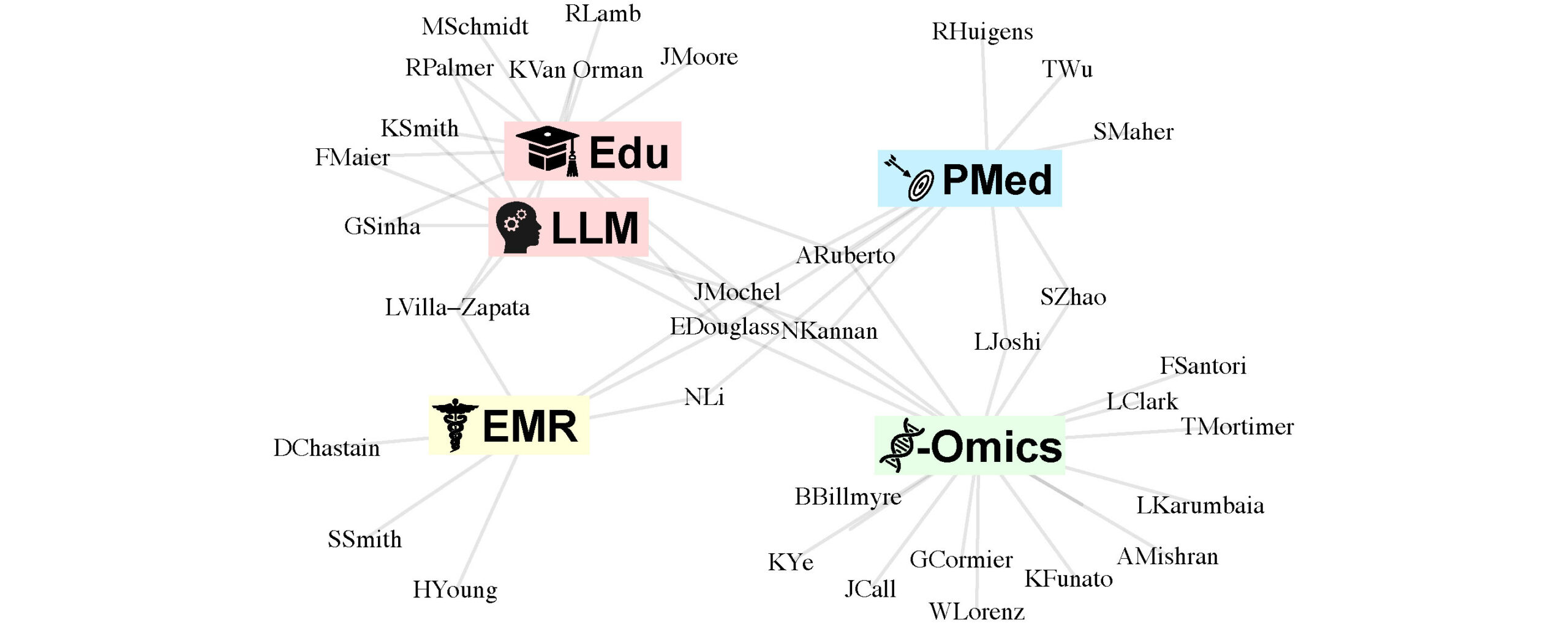
At the University of Georgia, our working groups are structured to harness collaborative expertise across various domains, fostering innovation and advancing research. The Omics working group unites researchers studying genomic, proteomic, and metabolomic datasets, with a current emphasis on transcriptomics due to emerging technologies. The Precision Medicine working group is dedicated to developing diagnostics and drug screening methods. Within this group, the Translational sub-group focuses on modeling clinical and in vivo drug responses. This group overlaps with the -Omics working group in the area of molecular diagnostics. The Drug Discovery sub-group specializes in drug design, virtual and experimental drug screening, and the analysis of drug-specific datasets to elucidate drug mechanisms, pharmacokinetics, and pharmacodynamics. Our Education working groups are divided into two main areas: training experimental scientists in basic data science tools, and enhancing traditional scientific and clinical education through virtual reality, augmented reality, and large language models. The Data Science sub-group creates new courses to train undergraduate and graduate researchers in SMDA laboratories, while the VR/AI Tools sub-group integrates these cutting-edge technologies into traditional courses. Finally, our Clinical working groups concentrate on electronic medical records and public health-related questions, leveraging data to improve healthcare outcomes and practices. Below is a network map of the current investigators within SMDA. If you are interested in joining the SMDA core contact Eugene Douglass at the contact information at the top of this page.